|
|
| Строка 1: |
Строка 1: |
| {{Статья|Черновик}} | | {{Статья|Черновик}} |
|
| |
| = Алгоритм ACCA =
| |
| В атмосфере Земли могут возникать различные помехи, которые могут попасть на снимки. В дальнейшем такие помехи затрудняют анализ данных. Например, облака могут закрывать поверхность Земли, тогда на снимке не видно, что находится под ними. Логично, что такие участки снимка анализировать бессмысленно, их нужно отбрасывать. Для этого были разработаны специальные алгоритмы. Для снимков со спутников серии LANDSAT был разработан алгоритм автоматической оценки облачности ACCA – (англ. Automatic Cloud Cover Assessment). Этот алгоритм позволяет классифицировать различные области снимка и создать из них маску. Подробно с алгоритмом можно познакомиться в статье [http://www.google.ru/url?sa=t&rct=j&q=&esrc=s&source=web&cd=1&sqi=2&ved=0CFMQFjAA&url=http%3A%2F%2Flandsathandbook.gsfc.nasa.gov%2Fpdfs%2FACCA_Special_Issue_Final.pdf&ei=BG74T9ihHfCKmQXgioWXBQ&usg=AFQjCNF_l2zuKrOoaxXOwPG9wF3-I8lJvQ&sig2=rKy0_sbASJQL_vJSlskJgg Richard R. Irish, John L. Barker, Samuel N. Goward, and Terry Arvidson, Characterization of the Landsat-7 ETM Automated Cloud-Cover Assessment (ACCA) Algorithm]
| |
|
| |
| В качестве входных данных алгоритм использует данные LANDSAT (4/5-я и 7-я версия спутника), преобразованные в спектральную отражательную способность. На выходе получается маска облачности.
| |
|
| |
| Алгоритм состоит из двух шагов, на первом шаге анализируются второй, третий, четвертый, пятый и шестой каналы и определяются следующие классы областей:
| |
|
| |
| * Холодное облако
| |
| * Теплое облако
| |
| * Тени (опционально)
| |
| * Возможно облако
| |
| * Не облако
| |
|
| |
| На втором шаге анализируется только шестой канал и области, которые на предыдущем шаге не получили однозначной оценки. В итоге в маске облачности могут присутствовать следующие категории областей:
| |
|
| |
| * Холодное облако
| |
| * Горячее облако
| |
| * Тени (опционально)
| |
| * Не облако
| |
|
| |
| Первый шаг состоит из 8-ми фильтров. Фильтр представляет собой некоторую операцию над какими-то слоями и отсев областей, в которых значение больше или меньше порогового. Каждый фильтр позволяет отбросить определенный класс областей. Комбинируя фильтры можно классифицировать облака.
| |
|
| |
| * Фильтр 1 – Порог яркости. Используется третий канал. Значения меньше порогового классифицируются как не облака. Остальные области переходят к фильтру 2.
| |
| * Фильтр 2 – NDSI (англ. Normalized Snow Difference Index) определяет заснеженные области. Используется второй и пятый каналы. Индекс NDSI считается по следующей формуле:
| |
|
| |
| <math>\mathit{NDSI}=\frac{\left(\left({\mathit{band}}_{2}-{\mathit{band}}_{5}\right)\right)}{\left(\left({\mathit{band}}_{2}+{\mathit{band}}_{5}\right)\right)}</math>
| |
|
| |
| Значения индекса выше порога классифицируются как снег и отбрасываются, остальные переходят к фильтру 3.
| |
|
| |
| * Фильтр 3 – Температурный порог. Значения свыше 300К (максимальная реальная температура облака) отбрасываются. Остальное переходит к фильтру 4.
| |
| * Фильтр 4 – Используются пятый и шестой каналы. Значения вычисляются по следующей формуле:
| |
|
| |
| <math>\mathit{value}=\left(1-{\mathit{band}}_{5}\right)\ast {\mathit{band}}_{6}</math>
| |
|
| |
| Все что больше порога классифицируется как «возможно облако», остальное переходит к фильтру 5.
| |
|
| |
| * Фильтр 5 – Используются третий и четвертый каналы. Значения вычисляются по следующей формуле:
| |
|
| |
| <math>\mathit{value}=\frac{{\mathit{band}}_{4}}{{\mathit{band}}_{3}}</math>
| |
|
| |
| Значения выше порога классифицируются как «возможно облако», остальное переходит к фильтру 6.
| |
|
| |
| * Фильтр 6 – Используются четвертый и второй каналы. Значения вычисляются по следующей формуле:
| |
|
| |
| <math>\mathit{value}=\frac{{\mathit{band}}_{4}}{{\mathit{band}}_{2}}</math>
| |
|
| |
| Значения выше порога классифицируются как «возможно облако», остальное переходит к фильтру 7.
| |
|
| |
| * Фильтр 7 – Используются четвертый и пятый каналы. Значения вычисляются по следующей формуле:
| |
|
| |
| <math>\mathit{value}=\frac{{\mathit{band}}_{4}}{{\mathit{band}}_{5}}</math>
| |
|
| |
| Значения ниже порога классифицируются как «возможно облако», остальное переходит к фильтру 8.
| |
|
| |
| * Фильтр 8 – Используются пятый и шестой каналы. Значения вычисляются по следующей формуле:
| |
|
| |
| <math>\mathit{value}=\frac{{\mathit{band}}_{5}}{{\mathit{band}}_{6}}</math>
| |
|
| |
| Значения выше и ниже порога классифицируются как теплые и холодные облака соответственно.
| |
|
| |
| Далее следует второй шаг, на котором рассматриваются только те области, которые не были однозначно идентифицированы и области, которые были определены как теплые облака (опционально). В процессе выполнения первого шага алгоритма собирается статистика по областям, которые соответствуют различным типам поверхности Земли. Например, считается процент снега на снимке, процент пустынь и скал и так далее. На основании этой статистики делается вывод, нужно ли пересматривать области, помеченные как теплые облака. В случае если на снимке более 1% площади занимает снег, то все области с теплыми областями помечаются как «возможно облако» и анализируются повторно. Если на снимке есть пустыни, то их процент тоже считается. Второй шаг выполняется, если выполняются три условия:
| |
|
| |
| * Площадь пустынь занимает более 50% снимка
| |
| * На снимке более 0.4% холодных облаков
| |
| * Средняя температура облаков меньше 295К
| |
|
| |
| Если условия не выполняются, то анализ температуры обходится и второй шаг завершается.
| |
|
| |
| Анализ температуры заключается в сравнении температуры областей, которые пересматриваются, с двумя значениями. Эти значения берутся из гистограммы, которая строится на первом шаге по температурным данным. Первое значение это температура на 83.5% (нижний порог) гистограммы, второе – 97.5% (верхний порог).
| |
|
| |
| Если температура области выше верхнего порога, то делается вывод что это не облако. Если ниже, то значение температуры сравнивается с нижним порогом. Те области, температура которых ниже, помечаются как холодные облака, в противном случае они помечаются как теплые облака.
| |
|
| |
| Далее маска облачности в окончательном виде сохраняется.
| |
|
| |
|
| = Интерфейс плагина = | | = Интерфейс плагина = |
| Строка 162: |
Строка 88: |
|
| |
|
| = Ссылки = | | = Ссылки = |
| | |
| | Описание алгоритма ACCA: [[http://wiki.gis-lab.info/w/Алгоритм_ACCA]] |
|
| |
|
| Исходный код: https://github.com/sergey-bastrakov/Acca-Plugin | | Исходный код: https://github.com/sergey-bastrakov/Acca-Plugin |
|
| |
|
| В процессе размещение плагина на http://plugins.qgis.org/ | | В процессе размещение плагина на http://plugins.qgis.org/ |
Эта страница является черновиком статьи.
Интерфейс плагина
Весь интерфейс представляет собой две формы, первая позволяет указать параметры алгоритма, вторая выводит прогресс выполнения.
|
|
 Рис. 2. Прогресс выполнения. |
После установки плагина в Quantum GIS, в меню появится пункт, вызывающий главное окно модуля. В появившемся главном окне необходимо указать два обязательных параметра:
- Путь до метафайла данных LANDSAT
- Путь до места, где будет сохранятся маска
Остальные параметры можно оставить по-умолчанию:
- Выполнять ли поиск облаков
- Использовать ли данные гистограммы по тепловому слою
- Выполнять ли один шаг
- Путь до преобразованных данных (По-умолчанию берется путь до папки с временными файлами вашей ОС)
После запуска алгоритма будет выведен прогресс выполнения, после чего программа завершается.
Внутреннее устройство плагина
Архитектура плагина
Функционально плагин можно разбить на несколько частей:
- TOAR – (англ. top-of-atmosphere radiance or reflectance and temperature) часть, которая вычисляет спектральную отражательную способность.
- ACCA – (англ. automatic cloud cover assessment) часть, которая содержит непосредственно алгоритм поиска облаков и построения маски облачности.
- Модуль для Quantum GIS – часть, которая обеспечит взаимодействие ГИС с алгоритмом ACCA
- Прочее – к этой части можно отнести различные модули, которые не попадают в вышеперечисленные категории. Например, файлы, которые содержат графический интерфейс, файлы содержащие описание модуля и так далее.
Блок-схема модуля:
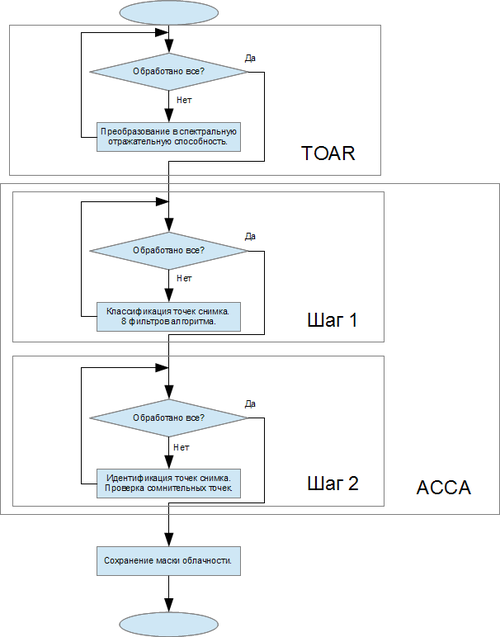
Рис 3. Блок-схема модуля. Реализация
Алгоритм преобразования данных LANDSAT
Для решения задачи преобразования данных LANDSAT был написан класс CToar, который включает в себя все необходимое для работы над снимком.
Снимок открывается с помощью библиотеки Gdal, она же предоставляет интерфейс для работы со слоями. Снимок в программе представляет собой набор двумерных массивов чисел – от 0 до 255 для каждого слоя. Каждый канал обрабатывается отдельно. С целью ускорения обработки канал разбивается на блоки 2000 на 2000 точек. Блоки обрабатываются сверху вниз слева направо.
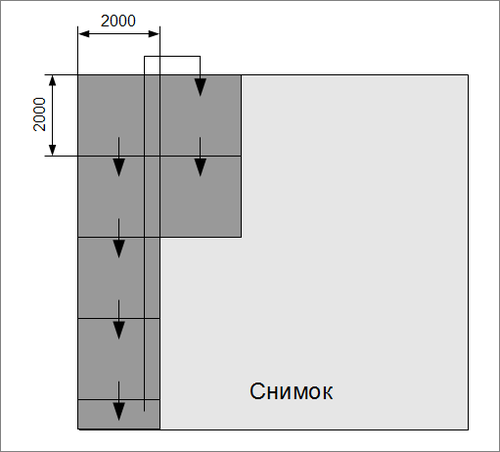
Рис. 4. Схема обработки снимка. Каждый блок обрабатывается целиком, библиотека NumPy позволяет выполнять поэлементные операции над массивами.
В зависимости от обрабатываемого слоя к снимку применяется свой набор операций. Сначала для каждого слоя рассчитывается плотность потока у датчика по формуле (1), далее для 2-5 каналов считается спектральная отражательная способность (2), а для теплового слоя температура (3).
Результат сохраняется в формате входных данных, кроме типа значений, у выходных данных тип float32.
UML диаграмма класса CToar:

Рис. 5. UML диаграмма класса CToar Обработка снимка происходит в функции processing, которая выполняется в своем потоке. Непосредственно вычисления производятся в функции toar.
Кроме обработки данных LANDSAT, необходимо произвести разбор метаданных и сохранить нужные для дальнейшей работы с алгоритмом ACCA. Разбор данных осуществляет функция parsing, а сохраняет нужные – save_metadata.
Процесс обработки снимков достаточно длительный, поэтому предусмотрен отладочный вывод, который становится активным при debuglevel=1. Так же в процессе обработки экземпляр класса CToar испускает сигнал progress, который может передавать информацию о прогрессе выполнения.
Алгоритм ACCA
Алгоритм содержится в классе CAcca. В состав класса входит весь необходимый для решения задачи функционал.
Обработка снимка происходит так же, как и в классе CToar. Снимок разбивается на блоки 2000 на 2000 точек. Но все каналы обрабатываются вместе. Так как в фильтрах проверяются значения из различных каналов.
При реализации класса CAcca основной проблемой являлась проверка каждой точки, проходит она фильтр или нет. Поточечная обработка заняла бы слишком много времени. Поэтому было принято решение использовать маски - двумерный массив булевых элементов. Для каждого фильтра строилась такая маска. Если значения элемента в маске True, то соответствующая точка снимка фильтр проходит. После каждого фильтра маска умножается на маску с предыдущего шага. В результате те точки, которые прошли все фильтры, будут иметь True в соответствующей точке маски. Классификация точек производится при помощи функции NumPy – putmask. Эта функция заменяет значения точек в маске облачности, соответствующих значениям True в маске фильтра, на заданное значение.
В процессе обработки снимка на первом шаге ведется статистика различных классов точек. На её основе делается вывод, что нужно сделать на втором шаге. Например, строится гистограмма для точек температурного слоя. Из неё берутся пороговые температуры для второго шага.
Процесс вычисления получился ресурсоемким, для запуска алгоритма требуется минимум 1ГБ оперативной памяти и порядка 1,5ГБ на жестком диске. От процессора зависит только скорость расчетов. На 4-х ядерном процессоре AMD A6 – 1,5 ГГц время выполнения составляет порядка 10 минут.
UML-диаграмма класса CAcca:

Рис. 6. UML диаграмма класса CAcca Точно так же как и в классе CToar функция processing, которая производит обработку снимка, выполняется в отдельном потоке. Здесь так же происходит вывод прогресса, если debuglevel=1 и точно так же испускается сигнал progress.
Результат работы алгоритма:
|
|
 Рис. 8. Итоговая маска, отредактированная для лучшего отображения. |
Ссылки
Описание алгоритма ACCA: [[1]]
Исходный код: https://github.com/sergey-bastrakov/Acca-Plugin
В процессе размещение плагина на http://plugins.qgis.org/







